ChatGPT APIの費用と始め方|業務自動化のコスト試算
ChatGPT APIの費用と始め方|業務自動化のコスト試算
ChatGPT APIの費用感は、単価表を見るだけではつかめません。実際には、入力と出力のトークン課金を前提に、自社の月間件数と1件あたりのテキスト量を掛け合わせて考えると、月額の概算が一気に現実的になります。
ChatGPT APIの費用感は、単価表を見るだけではつかめません。
実際には、入力と出力のトークン課金を前提に、自社の月間件数と1件あたりのテキスト量を掛け合わせて考えると、月額の概算が一気に現実的になります。
この記事は、Web版との違いを整理したうえで、業務自動化を検討する経営者やDX担当者が、用途別の試算式、モデル選定やBatch APIを含むコスト最適化、PoCから本番展開までの設計を通して判断できるようにまとめた内容です。
DX支援の現場では、月間件数×平均入力/出力トークン×単価でまず粗い見積もりを置き、その後に応答時間と再作業率をPoCのメトリクスへ落とし込むと、費用対効果の議論が止まりません。
費用は抑えるだけでなく、どの業務なら投資に見合うかまで設計してはじめて意味が出ます。
料金やモデル仕様は更新が続くため前提は2026年3月時点で整理しつつ、本稿では最新確認が必要なポイントと、セキュリティやROIまで含めた実務目線の考え方を一本で把握できる形にしました。
ChatGPT APIとは?Web版との違いをまず整理

ChatGPT Web版とAPIの本質的な違い
ChatGPTのWeb版とChatGPT APIは、同じOpenAIのモデル群を土台にしていても、使う前提がまったく異なります。
わかりやすく言うと、Web版はそのまま使える完成品のSaaSで、APIは自社システムに機能を埋め込むための開発インターフェースです。
前者はブラウザを開いて対話するサービス、後者は社内ポータル、FAQ、問い合わせ受付、文書処理フローなどに組み込むための部品だと捉えると整理できます。
費用の考え方もここで分かれます。
Web版は主に月額プランで利用する発想ですが、APIは入力トークンと出力トークンの両方に対して従量課金されます。
入力トークンはプロンプトや添付した文脈、指示文、過去の会話履歴などモデルへ渡すテキスト量です。
出力トークンはモデルが返す回答文そのものです。
つまり、同じ「1回の質問」でも、長い業務マニュアルを毎回渡して要約させるのか、短い質問だけ投げるのかでコスト構造は変わります。
ここで見落とされがちなのがトークンの感覚です。
日本語は英語よりトークン消費が増えやすい傾向があり、実務上の概算目安として「1,000文字 ≒ 1,000トークン前後」を使うことがあります。
ただし、句読点や英数字の混在、プロンプト構造で変動するため、正式な見積もりは代表データでトークンを実測して確認することを推奨します。
たとえば日本語の社内文書をそのまま長文で投げる運用は、英語中心の短い指示よりも入力課金が膨らみやすいという点に注意が必要です。
実務では、この違いは単なる料金の話で終わりません。
社内ポータル連携のPoCを設計したとき、Web版のままではユーザーごとの権限連携や監査ログの取り回しが噛み合わず、要件整理の時点で壁に当たりました。
誰がどの情報にアクセスできるのか、回答生成の記録をどこまで残すのか、個人情報を含むやり取りをどう制御するのかは、完成品のUIを使うだけでは吸収しきれません。
そこでAPI前提に切り替え、権限設計とログ設計を先に決めてから会話機能を載せる形にすると、監査要件と業務フローをひとつの設計図にまとめられました。
経営的に見ると、生成AIの導入可否を分けるのはモデル性能だけではなく、こうした周辺設計まで含めて自社で握れるかどうかです。
Responses APIと最新モデルの位置づけ
新規実装の入口としては、Responses APIを軸に考えるのが現在の整理です。
これは、従来の「チャットを返すAPI」という見方よりも広く、テキスト生成を中心に据えながら各種の応答処理をまとめて扱うための実装単位です。
業務システム側から見ると、会話ボットだけでなく、要約、翻訳、分類、情報抽出、文案生成、下書き作成、FAQ一次回答といった用途をひとつの発想で組み込みやすいのが特徴です。
ここで押さえたいのは、「ChatGPTを使う」ことと「APIで業務機能を作る」ことは同義ではないという点です。
APIの価値は、既存のデータや業務フローにつないだ瞬間に立ち上がります。
たとえば、問い合わせ本文を受け取ってカテゴリ分類し、社内ナレッジベースを参照して回答案を返し、必要なら担当部署へエスカレーションするといった処理は、Webアプリ単体の利用ではなくAPI実装で初めて業務の形になります。
そのときの費用見積もりは、モデル名だけ先に選んでも固まりません。
Responses APIで何をやるかを決め、1件あたりどれだけの入力トークンと出力トークンを使うかを置くことで、ようやく月間の概算が見えてきます。
たとえば分類なら出力は短く済みやすく、要約や文案生成は出力が伸びやすい、翻訳は入力も出力もほぼ同量になりやすい、といった違いがあります。
用途別のトークン構造を先に見るべき理由はここにあります。
なお、モデルや単価は更新サイクルが速いため、料金の基準はOpenAI API Pricingのページです。
見積もりのたたき台を作る段階では「どのモデルを使うか」よりも「何トークン流れるか」を先に置いた方が、あとでモデル差し替えが起きても再計算しやすくなります。
APIでできること・できないこと

APIでできることは広いです。
自然文の入出力を使う処理であれば、会話生成、要約、翻訳、文章の分類、タグ付け、FAQ応答、日報整理、問い合わせ一次受付、議事録の下書き生成など、多くの定型業務に乗せられます。
反復性があり、一定のルールで捌ける業務ほど相性が良く、工数削減や応答時間短縮の効果が見えやすくなります。
一方で、APIそのものが業務システムを完成させてくれるわけではありません。
ユーザー画面、承認フロー、権限制御、ログ保管、監査対応、エラー時の再実行、有人確認の導線は自社側で設計する領域です。
APIはあくまで知能部品であり、業務で使えるプロダクトにするには周辺機能が必要です。
ここを見誤ると、「回答は作れるのに運用できない」状態になります。
データの扱いも整理が必要です。
学習データとして長期保持されるかどうか、どの保持制御を選べるか、法人契約でどこまで統制できるかは、利用する設定や契約条件に紐づきます。
OpenAIは法人向けにデータ保持制御、Zero Data Retention、DPAやBAA、SOC 2 Type II、ISO/IEC 27001:2022、ISO/IEC 27701:2019などに関する情報を公開しており、セキュリティ設計は「生成AIだから曖昧」ではなく、通常のシステム導入と同じ粒度で詰めるべき領域です。
業務適性という観点でも線引きがあります。
FAQ一次回答や文書要約のように、正解の型がある仕事はAPI化しやすい一方、契約の最終判断、人事評価の確定、重要交渉の意思決定のように、責任判断や例外処理が中心の業務は主担当を人が持つ構成が前提になります。
PoCでは、応答時間、削減工数、満足度、再作業率といったKPIを先に置き、どこまでをAIが担当し、どこから人が引き取るかを明確にすると、導入後の評価がぶれません。
比較表: Web版 vs 標準API vs Batch API
Batch APIは24時間以内の非同期処理向けで、資料上は標準APIより低コストとなるケースがあります。
ただし、割引率や適用条件はサービス側の仕様・契約によって異なるため、見積もり時は公式ドキュメントで確認してください。
大量の翻訳、タグ付け、日報分析のような「急がないが件数が多い」仕事では、構成次第で費用差がそのまま収支差になります。
| 項目 | ChatGPT Web版 | 標準API | Batch API |
|---|---|---|---|
| 課金方式 | 主に月額プラン | 入力トークン・出力トークンの従量課金 | 入力トークン・出力トークンの従量課金 |
| 応答速度 | 対話利用向け | 即時応答向け | 24時間以内の非同期処理 |
| 自社システムへの組み込み | 低い | 高い | 高い |
| コスト最適化の考え方 | 利用上限やプラン範囲で管理 | モデル選定、プロンプト設計、トークン削減で管理 | 標準API比50%オフを活かして大量処理を集約 |
| 向く用途 | 個人利用、部門単位の試用、壁打ち | 社内アプリ、FAQ、問い合わせ導線、ワークフロー連携 | 日報分析、翻訳、タグ付け、夜間処理、一括要約 |
見積もりの前提をそろえるなら、まず「誰が使うか」ではなく「どの処理が何件流れるか」で分けると判断しやすくなります。
対話の即時性が必要なら標準API、翌朝までに終わればよい大量処理ならBatch API、個人の試用や軽い壁打ちならWeb版という切り分けです。
ここに日本語テキストのトークン増加傾向を重ねると、月額固定に見える利用と、従量で伸びる利用の境界が見えてきます。
経営的に見ると、生成AIの費用は「高いか安いか」ではなく、処理の性質に対して料金設計が合っているかで決まります。
ChatGPT APIの費用体系|入力・出力トークン課金の基本
トークンとは何か
ChatGPT APIの費用を読むときに最初につまずきやすいのが、「文字数」ではなく「トークン」で課金される点です。
トークンは、モデルがテキストを処理するときの細かな単位です。
日本語の文章をそのまま1文字ずつ数える感覚とは一致せず、単語、記号、改行、助詞の切れ目などを含んだかたまりとして分割されます。
わかりやすく言うと、APIは「1回いくら」で使うサービスではなく、入れたテキスト量と返ってきたテキスト量に応じて費用が積み上がる仕組みです。
ここで押さえたいのは、課金対象が入力だけではないことです。
ユーザーの質問、システムプロンプト、参照させる業務マニュアル、会話履歴など、モデルに渡す側が入力トークンとして課金されます。
モデルが返す回答文、要約文、分類結果、メール下書きなどは出力トークンとして別に課金されます。
つまりOnly pay for what you useの考え方で、月額固定ではありません。
1件ごとの入出力量が小さければ費用も小さくなり、長文の指示や長い回答を多く返す運用では、その分だけ増えます。
日本語はこの見積もりで少し注意が必要です。
英語に比べると、日本語はトークン消費が増える傾向があります。
実務上の概算目安として「1,000文字 ≒ 1,000トークン前後」を使うことがありますが、実際のトークン数は句読点・箇条書き・英数字混在・JSON形式指定などで増減します。
正式な見積もりを作る際は、代表データでトークン実測を取り、見積もりに反映してください。
費用が読み違えられる場面では、質問文そのものよりも、毎回添えている長い前提文がボトルネックになっていることが少なくありません。
たとえば社内FAQで、就業規則や手順書の抜粋を毎回そのまま渡していると、質問は短くても入力トークンが先に膨らみます。
逆に、回答を「3行で返す」「分類ラベルだけ返す」と決めると、出力トークンは抑えやすくなります。
経営的に見ると、API費用はモデル性能だけでなく、1件あたりの入出力量の設計で決まります。
料金ページの見方

料金を見るときの基準は、2026年3月時点ではOpenAI API Pricingです。
見るべきポイントはシンプルで、モデルごとに入力単価と出力単価が分かれていること、そして単価の表示が1Kトークンあたりであることです。
ここを取り違えると、見積もりが一桁ずれることがあります。
料金ページでは、同じモデル系統でも入力と出力で単価が異なる前提で読む必要があります。
要約や分類のように出力が短い用途なら、入力側の設計が費用に効きます。
文案生成や長文回答のように出力が伸びる用途では、出力単価の影響が強く出ます。
モデルを選ぶ場面で「高性能か、低コストか」だけを見ると判断が粗くなります。
実際には、どの業務で何トークン流れるかを先に置いたうえで、その処理量に対して単価を掛ける流れで見ると、費用の輪郭がはっきりします。
料金表を読む実務では、まず候補モデルを2つか3つに絞り、それぞれの入力単価と出力単価を同じ表に並べます。
そのうえで、想定業務を「FAQ一次回答」「要約」「翻訳」「分類」のように分けて、どの業務が入力寄りか、出力寄りかを見ます。
たとえば分類は出力が短く、翻訳は入出力が近づきやすく、長文回答は出力が費用を押し上げやすいという具合です。
この切り分けをしておくと、モデル変更があっても見積もりの再計算が崩れません。
費用最適化の選択肢としてBatch APIもこの段階で頭に入れておくと、試算の精度が上がります。
費用最適化の選択肢としてBatch APIもこの段階で頭に入れておくと、試算の精度が上がります。
即時応答ではなく、24時間以内の非同期処理でよい業務なら、標準APIより低コストになるケースがあり、用途と処理方式を分けて単価を見ることがコスト設計では欠かせません。
現場では、単価表を見てすぐに年間予算へ落とし込むより、先に代表ケースでトークン実測を取った方が精度が上がります。
PoCの早い段階で、実際に流す予定のデータから代表的な10件を選び、入力と出力のトークン数を測って平均値を出す進め方をよく使います。
問い合わせ文が短い業務と、社内文書を丸ごと投げる業務では、同じ「1件」でもまったく別のコスト構造になるからです。
単価表だけで机上計算するより、この10件の実測が入るだけで概算のブレが目に見えて小さくなります。
概算費用の計算式とサンプル計算
月額費用の概算は、次の式で置くと整理しやすくなります。
月額費用 ≒ 月間件数 × [(平均入力トークン ÷ 1000 × 入力単価) + (平均出力トークン ÷ 1000 × 出力単価)]
この式のポイントは、モデルごとに単価が違うことと、入力単価と出力単価を分けて計算することです。
1件単位の費用感を先に出して、それを月間件数に掛ける流れにすると、どこがコスト増の原因か見えます。
入力が長いのか、出力が長いのか、件数が多いのかを分けて議論できるためです。
たとえば、ある業務で月間件数を1,000件、平均入力を1,000トークン、平均出力を500トークンと置いた場合、1件あたりの費用は「入力1Kトークン分の単価」と「出力0.5Kトークン分の単価」を足したものになります。
その1件単価に1,000件を掛ければ月額の概算が出ます。
ここでは単価そのものはモデルごとに変わるため固定値は置きませんが、計算構造はこのままです。
翻訳のように入出力が近い処理なら両方が効き、分類のように出力が短い処理なら入力側の見直しが効果を出しやすくなります。
ℹ️ Note
概算の精度を上げるなら、想定ユースケースを平均1件で決め打ちせず、「短文・標準・長文」の3パターンに分けて試算すると、予算の上限と下限が見えます。
実務でよく起きるのは、平均入力トークンを甘く見積もってしまうケースです。
特に日本語の社内文書、議事録、規程集、問い合わせ履歴をそのまま渡す運用では、質問本文より補足コンテキストの方が長くなります。
そのため、概算ではまず代表10件の実データで平均入力と平均出力を測り、その値を式に入れると現実に近づきます。
ここで見えてくるのは、「1件の回答を賢くする」ほど入力が長くなりやすい一方で、業務によっては出力を短く制御するだけでも費用が締まるということです。
見積もりの前提をそろえるうえでは、件数だけでなく、1件あたりに何を渡すのかも明文化しておく必要があります。
システムプロンプト、参照文書、会話履歴、回答文字数の上限が曖昧なままだと、同じ業務名でも試算が人によって変わります。
PoCの段階でこの前提を固定し、平均トークンを実測しておくと、本番移行時の予算説明まで一気通貫で進められます。
業務自動化での費用目安|用途別の概算シミュレーション

シミュレーションの前提
概算を出すときは、まず「何の単価をどこに掛けるか」を固定します。
基準になるのはOpenAI API Pricingにある1Kトークンあたりの入力単価と出力単価です。
費用は月額でまとめて考えがちですが、実務では先に1件あたりの処理単位へ分解した方がブレません。
問い合わせ一次対応なら「ユーザーの質問文+参照FAQ+回答文」、議事録要約なら「会議本文+指示文+要約文」という形で、1件ごとの入力量と出力量を置いていきます。
式はシンプルで、月額の概算は次の形です。
月額費用 ≒ 月間件数 × {(平均入力トークン ÷ 1000 × 入力単価)+(平均出力トークン ÷ 1000 × 出力単価)+ 補助API分の従量費}
ここでいう補助APIには、前処理の抽出、後処理の分類、検索連携の追加処理などが入ります。
たとえばFAQ生成でも、原文をそのまま生成モデルへ渡すのか、先に見出し抽出や重複除去を挟むのかで、1件あたりのトークン量は変わります。
経営的に見ると、月間件数だけで予算を読むのではなく、1件の設計が何トークンで構成されているかを見える化した時点で、コストの調整余地が見えてきます。
日本語業務では、入力トークンが想定より膨らみやすい点も前提に入れておく必要があります。
社内文書や議事録は、言い回しの重複、あいづち、日時表現、署名、定型文が混ざるためです。
目安として日本語は英語よりトークンが増えやすく、同じ情報量でも入力コストが重くなります。
そのため、前処理で文を短く整える、不要な定型文を削る、項目名だけ英語化して構造をそろえるといった工夫が、そのまま見積もり精度と月額費用に効きます。
議事録要約の小規模PoCでは、この前処理設計の差がそのまま費用差になりました。
初回試算では会議本文をそのまま投入していましたが、実測すると平均入力トークンが想定の1.3倍まで膨らみました。
そこで、要約前に発話ノイズや重複を除去し、その後に要約結果からハイライトだけを別処理で抜き出す二段構成へ切り替えたところ、合計コストを2割ほど圧縮できました。
汎用化すると、長文を一気に処理するより、不要部分を先に削ってから、目的ごとに処理を分ける方が費用と品質の両面で整いやすい場面があります。
用途別の概算費用シミュレーション表
用途別の見積もりでは、単価の固定値を書き込むより、変数ベースで残した方が再利用しやすいです。
モデル変更があっても、入力単価と出力単価を差し替えるだけで再計算できるからです。
下の表では、標準APIの入力単価を「Pin」、出力単価を「Pout」と置いています。
Batch APIは非同期で処理を集約できる用途に向くため、概算式では標準API費用の0.5倍で表しています。
| 用途 | 想定入力トークン/件 | 想定出力トークン/件 | 月間件数 | 標準APIの概算式 | Batch APIの概算式 |
|---|---|---|---|---|---|
| 問い合わせ一次対応 | Tin_inquiry | Tout_inquiry | N_inquiry | N_inquiry × {(Tin_inquiry/1000 × Pin)+(Tout_inquiry/1000 × Pout)} | 0.5 × 標準API費用 |
| 議事録要約 | Tin_minutes | Tout_minutes | N_minutes | N_minutes × {(Tin_minutes/1000 × Pin)+(Tout_minutes/1000 × Pout)} | 0.5 × 標準API費用 |
| 社内ヘルプデスク | Tin_helpdesk | Tout_helpdesk | N_helpdesk | N_helpdesk × {(Tin_helpdesk/1000 × Pin)+(Tout_helpdesk/1000 × Pout)} | 0.5 × 標準API費用 |
| 翻訳 | Tin_translate | Tout_translate | N_translate | N_translate × {(Tin_translate/1000 × Pin)+(Tout_translate/1000 × Pout)} | 0.5 × 標準API費用 |
この表の見方は単純で、各用途についてまず1件の平均入力トークンと平均出力トークンを決め、そのうえで月間件数を掛けます。
問い合わせ一次対応は、質問文そのものよりも、参照FAQや会話履歴の付与で入力が増えやすい構造です。
議事録要約は長文入力になりやすく、要約文を短く抑えても、入力側の占める比率が大きくなります。
FAQ生成は、元資料の量と生成するQ&A件数の設計で入出力の両方が動きます。
社内ヘルプデスクは、就業規則や手順書の参照範囲を広げるほど入力が増え、翻訳は入出力が近い長さになりやすいので、両方の単価が効いてきます。
実務では、ここに「補助APIの有無」を1列加えることがあります。
たとえば社内ヘルプデスクで、質問分類を先に短い処理で回してから本回答へ渡す構成にすると、メイン処理へ不要な文書を渡さずに済みます。
議事録要約でも、全文要約、決定事項抽出、ToDo抽出を一気にやるより、工程を分けた方が総トークンが下がることがあります。
1件あたりの設計を揃えたうえで表に落とすと、単価そのものより、どの用途が入力過多なのかが見えてきます。
💡 Tip
[!NOTE] 概算表は「短文ケース」「標準ケース」「長文ケース」の3列を持たせると、月間予算の上下幅まで読めます。平均値ひとつだけの試算より、稟議やPoC設計で使える数字になります。
小規模PoCから始める設計

PoCでは、最初から全社件数を前提にした設計より、100〜500件/月規模の小さな検証の方が意思決定に直結します。
理由は明快で、費用だけでなく品質も同時に測れるからです。
問い合わせ対応なら回答時間、要約なら人手修正の有無、社内ヘルプデスクなら解決率のように、KPIとトークン実測をひとつの表で管理できます。
机上の平均値より、実データのばらつきが見える方が本番予算に結びつきます。
この段階では、代表的な処理を集めて平均トークンを測り、月間件数に当てはめて補正していきます。
実際には、短文の問い合わせばかりだと思っていた業務でも、履歴添付や社内ルール引用で入力が伸びることがあります。
逆に、回答を簡潔な定型へ寄せるだけで出力トークンが下がり、見積もりが締まる場面もあります。
PoCで見るべきなのは、モデルの賢さだけではなく、どこでトークンが膨らみ、どこを削っても品質が落ちないかです。
経営的に見ると、この小規模検証はコスト確認のためだけではありません。
ROIの見方は、削減できた時間を人件費へ置き換えると輪郭が出ます。
たとえば月30時間の短縮が10人に広がる業務なら、時給3,000円換算で月約90万円の削減余地になります。
API費用の概算と、この工数削減を並べると、単なる「ツール費」ではなく、投資対効果として議論できます。
PoCで件数、トークン、品質、削減時間をまとめて取る設計は、この比較を行うための土台になります。
この順番で組むと、本番移行の時点で「どの業務に、どのモデルを、どの処理方式で当てるか」が数字で説明できる状態になります。
ここではResponses APIなど技術名をそのまま指すより、実際に1件あたり何トークン流れるか、対応速度と品質がどう変わるかを示すことが欠かせません。
コストを抑える方法|モデル選定・プロンプト設計・キャッシュ・Batch API
モデル選定の原則
コスト最適化は、単価表を見て安いモデルを選ぶことでは終わりません。
実際には、入力課金と出力課金の両方が積み上がるため、どの処理にどのモデルを当てるかで総額が変わります。
前述の通り、APIはトークン単位の従量課金です。
わかりやすく言うと、送る文章量と返ってくる文章量の両方に費用がかかる構造なので、モデルの性能差だけでなく、1件あたりの入出力量まで含めて設計する必要があります。
このときの原則は明快で、小さいモデルから試すことです。
分類、タグ付け、FAQ下書き、短い要約のように、判断パターンがある程度決まっている業務は、低コストモデルでも十分に要件を満たす場面が少なくありません。
反対に、複雑な推論、曖昧な文脈の読解、専門性の高い文案調整のような処理は、高性能モデルの方が手戻りを減らせます。
全件を高性能モデルで統一すると、品質は安定しても、過剰品質のままコストを払い続ける構図になりがちです。
そこで現実的なのが、ハイブリッド戦略です。
たとえば一次分類や下書き生成は低コストモデルで回し、一定条件を満たした案件だけ高性能モデルへ渡します。
経営的に見ると、この設計は「精度を落とさずに単価の高い処理回数を減らす」ことに直結します。
モデル選定は、1モデルを決める作業というより、業務フローのどこに高単価処理を置くかを決める作業です。
日本語運用では、この切り分けがいっそう効いてきます。
日本語は英語よりトークンが増えやすく、1,000文字でおおむね1,000トークン前後を見込む場面があります。
つまり、同じ意味の指示でも日本語のまま長く書くほど入力課金が膨らみやすいということです。
社内の内部処理を英語寄りの短い命令テンプレートで統一し、外部表示だけ日本語へ整える構成にすると、用途によってはトークン総量を抑えられます。
もちろん翻訳工程が増えるので万能ではありませんが、FAQ下書きや分類結果の整形のように構造が定まっている仕事では検討余地があります。
料金の見積もりで前提を揃えるうえでは、モデル名ごとの細かな単価を固定値で覚えるより、最新料金はOpenAI API Pricingを基準に扱う方が実務向きです。
モデルと料金は更新されるため、稟議やPoCの数字もその前提で作る方がぶれません。
プロンプトと出力長の制御ポイント

API費用はモデル選定だけでなく、何をどれだけ送って、どこまで返させるかで大きく変わります。
特に見落としやすいのが出力側です。
入力ばかり削ろうとしても、回答を長く返す設計になっていると、出力課金が積み上がります。
ここで押さえたいのが、max_output_tokens の制御と、回答形式の固定です。
たとえば「丁寧に説明してください」と書くと、モデルは安全側に倒れて文章を長くしがちです。
一方で「300字以内」「箇条書き3点」「JSONで項目名のみ返す」のように枠を決めると、出力の揺れが減り、費用の予測も立てやすくなります。
業務自動化では、文学的な表現力より、必要な項目が規定の長さで返ることの方が価値になります。
出力長の上限を設けるだけで、月次コストの変動幅が目に見えて落ち着くケースは珍しくありません。
会話履歴の扱いも同じです。
チャット形式の実装では、過去ログをそのまま積み増して送る構成になりやすいのですが、これが入力課金を押し上げる典型です。
必要な履歴だけ残し、完了したやり取りは要約して圧縮する方が合理的です。
社内ヘルプデスクや問い合わせ対応では、「今の質問に必要な前提」だけを再構成して渡す設計の方が、精度もコストも安定します。
FAQ自動下書きの運用でも、この差ははっきり出ます。
実務では、担当者ごとにプロンプトの書き方が揺れると、同じ件数でもトークン量がぶれます。
そこで要件を箇条書きのテンプレートに固定し、想定読者回答トーン禁止表現出力項目を短い定型文で揃えると、入力のばらつきが収まります。
圧縮プロンプトも有効です。
長い説明文を毎回そのまま送るのではなく、役割・条件・出力形式を短い記法でまとめると、意味を保ったまま入力トークンを減らせます。
日本語は記述が丁寧になるほど文字数が伸びやすいため、ここでもトークン増加の影響を受けます。
簡潔な内部命令に寄せるだけで、件数が増えたときの差が効いてきます。
⚠️ Warning
[!NOTE] コストを安定させたい運用では、「モデル」「入力テンプレート」「出力上限」の3点を固定し、例外案件だけ別フローへ逃がす構成が収まりやすい形です。全件で自由入力にすると、件数が同じでも月額がぶれます。
Context Cachingの使いどころ
長いシステムプロンプトや共通前提を毎回送っているなら、コスト削減の余地はモデル変更より大きいことがあります。
そこで効くのがContext Cachingです。
考え方は単純で、毎回同じ内容を再送せず、繰り返し使うコンテキストを活かす設計にするというものです。
向いているのは、会社概要、ブランドトーン、FAQ作成ルール、評価基準、出力フォーマット定義のように、案件が変わってもほぼ固定の情報です。
たとえばFAQの自動下書きでは、「敬体で書く」「断定しすぎない」「1回答1テーマ」「見出し構成を揃える」といった長めの共通ルールを毎回送る構成になりがちです。
この部分を都度送信すると、1件ごとの差は小さく見えても、月間件数が増えた段階で入力課金に影響してきます。
共通前提をキャッシュを前提に整理すると、案件ごとに送るべき情報は質問文と追加条件に絞れます。
この設計の価値は、単なる削減額だけではありません。
入力が短く均一になるため、プロンプト管理の難易度が下がります。
担当者が変わっても、固定コンテキストの中で動くので、品質のばらつきも抑えやすくなります。
FAQ運用でコスト変動を落ち着かせられた背景もここにあり、キャッシュそのものより、共通前提を分離して再利用できる形に整理したことが効きました。
キャッシュの割引率は仕様に紐づくため、数値を前提に稟議へ書くならOpenAI API Pricing側の最新条件で揃えるのが筋です。
このセクションで押さえたいのは率そのものより、長い固定文を何度も送る運用は、そのままムダな入力課金になるという構造です。
特に日本語の長文ガイドラインを丸ごと入れているケースでは、見直しの余地が大きく残っています。
標準APIとBatch APIの使い分け表
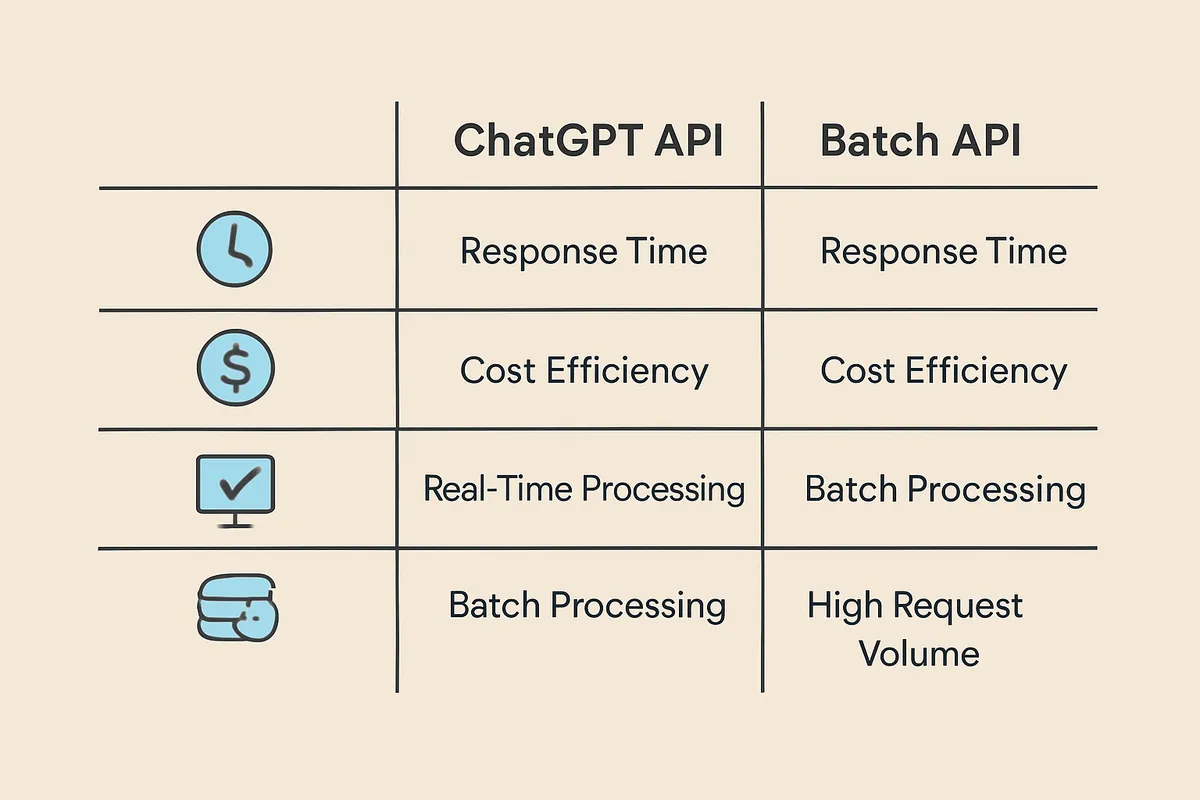
即時応答が必要かどうかで、コスト構造は変わります。
問い合わせ画面の返答や社内チャット支援のように、その場で結果が必要な業務は標準APIが前提です。
一方で、日報要約、翻訳、タグ付け、FAQ案の一括生成のように、即時性より件数が支配的な業務は、非同期処理へ分けた方が収支が整います。
Batch APIはこの切り分けで効いてきます。
下の表は、標準API、Batch API、Context Cachingを含めた使い分けの整理です。
費用の見方では、どれが安いかを単純比較するより、いつ返す必要があるか、共通前提をどれだけ再利用できるかで決める方が失敗しません。
| 項目 | 標準API | Batch API | キャッシュ活用前提のAPI運用 |
|---|---|---|---|
| 項目 | 標準API | Batch API(割引率は要確認) | キャッシュ活用前提のAPI運用 |
| ------ | ------ | ------ | ------ |
| 即時性 | 即時応答向け | 24時間以内の非同期処理 | 即時応答にも非同期処理にも組み込める |
| コスト | 基本の従量課金 | 場合により標準APIより低コスト(割引率は要確認) | 長い共通コンテキストの再送分を圧縮できる |
| 実装難易度 | 中程度 | 中〜高程度 | 中程度 |
| 向くタスク | 社内アプリ、チャットUI、問い合わせ一次対応 | 日報分析、翻訳、タグ付け、夜間一括要約 | FAQ生成、社内ヘルプデスク、共通ルールが長い業務 |
| 向かない場面 | 件数が多く即時性が不要な大量処理 | 画面上で即答が必要な業務 | 共通前提が短く、毎回入力内容が大きく変わる業務 |
| 設計の勘所 | 出力長と履歴を抑える | 急がない処理をまとめる | 固定ルールと案件固有情報を分離する |
実務では、この3つを排他的に選ぶというより、組み合わせて使います。
たとえば日中の問い合わせ一次回答は標準API、夜間のFAQ候補作成はBatch API、どちらにも共通する運用ルールはContext Cachingで持つ、という構成です。
こうすると、即時性が必要な場所だけ通常コストを払い、件数の多い裏側処理は割引を取りに行けます。
見積もりの前提を揃えるうえで押さえたいのは、APIコストは「モデル単価」だけでは決まらないということです。
入力課金や出力課金、トークン量、日本語の増え方、処理方式の切り分けまで含めて初めて現実的な見積もりになります。
単価表だけで高い・安いを判断すると、設計で下げられる費用を見落としがちです。
ここまで整理しておくと、次にPoCや本番設計へ進んだときに、どこで予算が膨らみ、どこで抑えられるかを説明しやすくなります。
ChatGPT APIで自動化しやすい業務と向かない業務
自動化に向く業務の条件と例
ChatGPT APIを業務へ組み込むときは、「AIで何ができるか」より先に、「その業務がどんな構造か」を見る方が見積もりの精度が上がります。
線引きの軸になるのは、反復性、ルール化のしやすさ、例外の頻度です。
同じ問い合わせ対応でも、毎回ほぼ同じ型で処理できるものと、背景事情を細かく読み取らないと答えられないものでは、向いている設計が変わります。
自動化と相性がよいのは、入力の型がある程度そろっていて、期待する出力も定型化できる業務です。
たとえばFAQの一次回答案、社内文書の要約、議事録の整理、翻訳、問い合わせ内容の分類、商品説明文やメール文案の下書きは、この条件に当てはまりやすい領域です。
こうした業務は「何を入れるか」と「どう返すか」をテンプレート化しやすく、品質確認も比較的回しやすくなります。
このとき費用感を左右するのが、前のセクションでも触れた入力課金と出力課金です。
ChatGPT APIは入力トークンと出力トークンの両方で従量課金になるため、定型業務ほどトークン量の見通しを立てやすくなります。
たとえば問い合わせ分類なら、入力は質問文と最低限の属性情報、出力は分類ラベルと短い理由で済むため、1件ごとのトークン量が読みやすい構成になります。
日本語は英語よりトークンが膨らみやすい傾向があるので、日本語の社内文書をそのまま長く渡す運用では、件数が同じでも費用が伸びやすくなります。
実務では、1,000文字の日本語を入れると、概算ではそのまま1,000トークン前後の感覚で見ておくと見積もりがぶれにくくなります。
実際に相性がよかったのは、社内問い合わせの一次分類です。
質問文を受けて「人事」「総務」「情報システム」「経理」などに振り分ける処理は、ルールが明確で、誤りが出ても後段で補正できます。
就業規程や経費規程の解釈そのものを確定させる工程まで任せると、似た質問でも前提条件の差で答えが割れます。
この境目で承認フローを残した設計の方が、現場の納得感も品質も安定しました。
AIには入口の整流化を任せ、人は最終判断に集中する形の方が、導入後に運用が崩れません。
業務特性ごとの整理は、次のように置くと判断しやすくなります。
| 区分 | 業務の特徴 | 例 | 期待できる効果 | 運用要件 |
|---|---|---|---|---|
| 自動化に向く | 反復的でルール化しやすく、例外が少ない | FAQ一次回答、要約、翻訳、問い合わせ分類、文案生成 | 工数削減、応答速度の向上、属人化の低減 | 入出力フォーマットの固定、KPI設計、定期的な品質確認 |
| 条件付きで向く | 基本は定型だが、一部に判断や確認が必要 | 社内ヘルプデスク、文書レビュー補助、ナレッジ検索支援 | 情報探索時間の短縮、下書き作成の高速化 | 人のレビュー併用、エスカレーション条件の明確化 |
| 向きにくい | 例外が多く、責任の重い最終判断を含む | 契約確定判断、人事評価の最終決定、重要交渉 | 誤判断の回避が優先 | 原則として人が主担当、AIは補助に限定 |
経営的に見ると、この分類はそのまま予算設計にもつながります。
自動化に向く業務ほど1件あたりのトークン量と件数が読みやすく、費用対効果の説明も組み立てやすくなります。
逆に、毎回長い事情説明が必要な業務は、入力トークンが膨らみやすく、しかも人の確認工数も残るため、見た目ほど収支が合いません。
用途選定の段階で業務特性を切っておくことが、PoCの成功率を左右します。
条件付きで向く業務

次に検討したいのが、「全部自動化は難しいが、部分的に組み込むと効果が出る」業務です。
ここで多いのは、情報整理や下書き作成まではAIに任せられるものの、確定前に人の確認が必要なケースです。
社内ヘルプデスク、稟議文のレビュー補助、規程を踏まえた回答案の生成、営業メモの要点整理などが典型です。
この領域では、AIの役割を「回答者」ではなく「前処理担当」や「下書き担当」として置くと、運用が安定します。
たとえば社内ヘルプデスクでは、質問の意図を整理し、関連する候補文書を引き当て、回答案を整えるところまでをAIが担い、送信前の確認は担当部門が行う形です。
これなら、検索にかかる時間や文章作成の初動を短縮しつつ、誤案内のリスクを抑えられます。
条件付きで向く業務は、費用面でも設計の差が出やすい領域です。
入力課金と出力課金の考え方は同じでも、確認対象の文書が長くなるほど入力トークンが増えます。
日本語の規程集、就業ルール、手順書をそのまま毎回流し込む構成だと、1件の処理単価が想定より伸びやすくなります。
反対に、参照範囲を絞り、出力も「要点3つ」「該当箇所の候補提示」「回答案200字以内」といった形に制御すると、トークン消費を読みやすくできます。
見積もりで前提をそろえるには、業務名ではなく、1件あたり何文字を入れて何文字を返すかまで分解して考える必要があります。
モデル選定でも、この区分は効いてきます。
分類、要約、短い下書きのような定型寄りの処理は、低コスト側のモデルでも収まりやすい一方、長文の文脈理解や複数条件の比較が入る業務では、精度を優先した方が手戻りが減る場面があります。
現場では、全件を高性能モデルに寄せるより、定型部分は低コストモデル、確認が難しい案件だけ高性能モデルへ回すハイブリッド運用が現実的な落としどころになりやすいのが利点です。
費用は単価だけでなく、再作業率と確認工数まで含めて見ないと判断を誤ります。
💡 Tip
条件付きで向く業務は、「AIが返した内容をそのまま採用してよい場面」と「人が確定させる場面」を先に分けておくと、品質と費用の両方が安定します。運用開始後に境界線を探り始めると、例外処理が増えて収まりません。
ここでも単価の基準はOpenAI API Pricingの掲載内容です。
モデル名や料金は更新されるため、稟議や試算ではその時点の公式Pricingページを基準にそろえるのが前提になります。
条件付きの業務ほど、入力文量とモデル選択で金額差が出るため、業務担当者の感覚値ではなく、実際のサンプルデータでトークン数を取っておく方がぶれません。
向きにくい業務とリスク管理
向きにくい業務は、AIの性能が足りないからというより、業務側の責任構造が重いことが理由になる場合が多いです。
契約の最終確定判断、人事評価の最終決定、懲戒や採用可否の判断、重大なクレーム対応、重要取引先との条件交渉などは、例外処理が多く、背景事情の読み違いがそのまま損失や信用低下につながります。
ここは人が主担当であるべき領域です。
こうした業務でも、AIの出番がゼロになるわけではありません。
論点整理、比較観点の洗い出し、過去文書の要約、会議前のたたき台作成といった補助用途には価値があります。
ただし、補助と判断を混同すると運用事故が起こります。
特に、「それらしい文章」が返る業務ほど、内容の妥当性より文章の滑らかさに引っ張られやすくなります。
向きにくい業務では、AIの役割を補助に限定し、承認権限や責任所在を人側に固定しておく設計が欠かせません。
費用の面でも、この区分は見落とせません。
向きにくい業務は背景説明が長くなりやすく、入力トークンが増えます。
そのうえ、慎重な確認のために出力も長文化しやすく、入力課金・出力課金の両方が積み上がります。
日本語の複雑な事情説明や複数資料の引用が入ると、定型業務よりトークン量が伸びやすく、しかも人のレビュー工数も削れません。
結果として、「API費用は払っているのに、意思決定は結局人がやる」という構造になりやすく、ROIが出にくくなります。
この領域で見るべきKPIも、単純な件数処理ではなく、再確認率、差し戻し率、誤案内率、承認までのリードタイムなどになります。
AIで短縮できるのは、判断そのものではなく、判断材料の整理までという整理が妥当です。
人材不足の補完という観点では魅力的に見えても、責任の重い判断をAIへ寄せると、運用ルールの整備コストと監査コストが先に膨らみます。
業務適用の線引きは、技術論だけでなく統制設計の問題です。
自動化に向く業務は、入出力の型をそろえてトークン量を読み、条件付きで向く業務は人の確認を前提に収支を計算し、向きにくい業務は補助用途にとどめる。
この順番で整理すると、どこに投資すべきかが見えやすくなります。
料金の最終基準はOpenAI API Pricingの公式ページに置きつつ、実際の見積もりは業務特性と日本語テキスト量まで落として考えることが、現実的な予算設計につながります。
導入の進め方5ステップ|PoCから本番運用まで

ステップ1: 対象業務の選定基準
導入の起点は、どの部署で使うかではなく、どの業務単位で切り出すかです。
実装経験がない段階でありがちな失敗は、「問い合わせ対応をAI化する」「営業を効率化する」といった広いテーマから入ってしまうことです。
これでは対象範囲が大きすぎて、工数も品質も測れません。
わかりやすく言うと、最初は1件ごとの入出力が想像できる仕事に絞るべきです。
たとえばFAQ一次回答、議事録要約、日報のタグ付け、社内規程の検索補助のように、入力と出力の型がある程度そろう業務が適しています。
選定時は、即時性、月間件数、平均入力長と平均出力長、機密性の4点を見ると整理が進みます。
即時性が高い業務は標準API向きで、夜間処理や翌営業日までに終わればよい業務は非同期設計に寄せられます。
月間件数が少ない業務は効果が見えにくく、逆に件数が多い業務は小さな改善でも収支に効きます。
さらに、平均入力長と平均出力長を見ておくと、後の費用試算が業務名ベースの感覚論になりません。
機密性も同時に確認し、顧客情報、契約情報、人事情報のように取り扱いの条件が厳しいものは、最初のPoC対象から外すか、匿名化したデータで扱う設計にした方が進行が安定します。
経営的に見ると、最初に選ぶべきなのは「精度が少し揺れても人の確認で吸収できるのに、件数は多い業務」です。
反対に、件数が少なく、判断責任が重く、入力文も長い業務を最初に選ぶと、費用も評価もぶれます。
導入初期は、AIに意思決定を任せる領域ではなく、前処理や下書き作成の領域から着手した方が、投資判断の材料がそろいます。
ステップ2: 現状工数と品質の見える化
対象業務が決まったら、次に行うのは「現状把握」です。
ここで必要なのは、現場の印象ではなく、業務が今どれだけの時間と品質コストを消費しているかを数値化することです。
最低限そろえたいのは、1件あたりの処理時間、月間処理件数、担当者数、SLA、再作業率、誤回答や誤処理が起きたときの影響度です。
工数はh単位で集計し、どこに時間がかかっているかを分解します。
問い合わせ対応なら、内容確認、関連資料の検索、文案作成、上長確認、送信後修正といった工程に分けると、AIが削れる部分と削れない部分が見えます。
品質も同じように分解して見る必要があります。
単に「今もそこまで困っていない」で終えると、PoC後の比較ができません。
SLAを守れているか、再作業がどの程度発生しているか、誤回答が起きた場合に顧客対応のやり直しで済むのか、それとも信用毀損につながるのかで、許容できる自動化の深さが変わります。
ここを曖昧にすると、導入後に速度は上がったのに品質評価で止まる、あるいは品質は高いのに費用が見合わないという、よくあるねじれが起こります。
実務では、この段階で「どの指標を追うか」を増やしすぎると会議が進みません。
PoCレビュー会では、KPIを速度・コスト・品質の3つに絞るだけで議論の軸がそろい、部門間の意思決定が一気に速くなります。
速度には応答時間や処理完了までの時間、コストには1件あたりのAPI費用と削減工数、品質には正答率や再作業率を置く形です。
指標を増やすほど精緻に見えますが、初期段階では比較可能な形で継続計測できることの方が価値があります。
ステップ3: PoC設計
PoCでは「作れるか」ではなく「本番に値するか」を判定します。
そのため、代表データの作り方が成否を左右します。
うまくいった例だけを集めても意味がなく、実際の運用で出る典型ケース、少し複雑なケース、失敗しやすいケースを含めて評価用データを用意する必要があります。
問い合わせ業務なら、短い質問、あいまいな質問、社内規程の参照が必要な質問、回答してはいけない質問を混ぜる、といった設計です。
これで精度だけでなく、どこで破綻するかが見えます。
⚠️ Warning
実装方針は、現時点ではResponses API前提で組むのが自然です。
単発のやり取りで終わるのか、ツール連携を含むのか、ログ設計をどうするのかを最初に決めておくと、PoCの成果がそのまま本番設計のたたき台になります。
プロンプトだけで帳尻を合わせようとするより、入力の整形、参照データの絞り込み、出力形式の固定、人の確認導線まで含めて設計した方が、評価結果が現実に近づきます。
⚠️ Warning
PoCは「成功例を作る場」ではなく、「本番で事故になる条件を先に見つける場」です。精度の高さだけで判定すると、本番移行後に運用負荷が噴き出します。
ステップ4: KPIとコストの同時計測
PoCが始まったら、KPIとコストを同じ表で追うことが欠かせません。
品質だけ見ていると高性能モデルへ寄りすぎ、費用だけ見ていると再作業が増えて現場が疲弊します。
見るべき指標は、応答時間、削減工数、処理件数、利用者満足度、APIコスト/件、品質指標です。
品質指標には、正答率、再作業率、差し戻し率、エスカレーション率など、業務に合うものを置きます。
問い合わせ一次対応なら、初回回答までの時間と有人修正率の組み合わせが見やすく、要約業務なら、作成時間短縮と修正回数の組み合わせが相性のよい見方です。
コストは月額合計だけでなく、1件単位まで落として見る必要があります。
件数が増える業務では、1件あたりの差がそのまま月次費用の差になります。
工数削減と並べると、収支が判断しやすくなります。
たとえば月30時間の短縮が10人規模に広がると、時給3,000円換算で月約90万円の削減余地になります。
この形で人件費削減効果とAPI費用を同じ土俵に並べると、単なるシステム費ではなく、業務改善投資として評価できます。
また、処理方式の違いもKPI表に入れておくと判断がぶれません。
即時応答が必要な業務と、夜間にまとめて流せる業務では、設計の前提が違います。
大量処理を抱える業務なら、非同期実行を含めた構成の方が収支が合う場面があります。
PoC段階から、リアルタイム処理とまとめ処理を分けて記録しておくと、本番化の時点で構成変更の判断材料になります。
ステップ5: 本番運用と監視体制
本番化の判断は、PoCで一定の精度が出たかだけでは足りません。
運用ルール、監視、権限管理、データ取り扱いまで含めて、継続運用できる状態になっているかを見る必要があります。
判断基準としては、KPIが継続的に安定していること、人の確認工程が現場負荷として回ること、失敗時の切り戻し手順があること、責任部門が明確であることが前提になります。
ここが固まっていないまま本番へ進むと、導入直後は動いても数週間で運用が詰まります。
監視体制では、アラート、ログ、モデル更新への追随、データ保持ポリシーの定期見直しをセットで考えます。
アラートは応答失敗、タイムアウト、異常な件数増加、想定外の長文出力など、運用停止や費用膨張につながる事象に絞ると管理しやすくなります。
ログは、誰が、どの業務で、何を入力し、どのような出力が返り、最終的に採用されたかまで追える形が望まれます。
モデル更新は精度改善の機会である一方、出力傾向の変化も起こるため、定期評価の運用が必要です。
データ保持ポリシーも固定で終わらせず、業務の拡大や対象データの変化に合わせて見直す前提で置くべきです。
この段階では、チェックリスト形式で抜け漏れを管理すると運用設計が崩れません。実務で最低限そろえたい観点は次の通りです。
- セキュリティと契約条件の整理
- データ取り扱い範囲の明確化
- APIキーを含む鍵管理の手順化
- 利用部門ごとの権限設定
- 監査ログの保存と確認フロー
本番運用に入ると、技術の精度よりも、異常時に誰が止めて誰が直すかの方が支配的になります。
導入の成否はPoCの出来より、運用と監視の設計で決まる場面が多く、ここまで含めて初めて業務自動化として成立します。
費用対効果の見方|ROIを測るKPI例
KPIの設定例と測定方法
費用対効果を見るときは、APIの月額だけを追っても経営判断にはつながりません。
経営的に見ると、どれだけ早くなったか、何件さばけるようになったか、どれだけ人手が減ったか、品質が落ちていないかを同時に見る必要があります。
ChatGPT APIのような生成AIは、処理コストと業務効果の両方が数字で出るため、KPIを最初から表で定義しておくと議論がぶれません。
現場で置きやすいKPIは、応答時間短縮、削減工数、対応件数、満足度、再作業率、1件あたりAPIコスト、誤回答率です。
たとえば問い合わせ一次対応なら、導入前後で「初回回答までの時間が何分縮んだか」「担当者1人あたりの月間対応件数がどう変わったか」を見ます。
議事録要約や文書作成補助なら、「1件の作成にかかる所要時間」と「人手での修正回数」を置くと、効果と品質が同時に見えます。
満足度は社内利用でも有効で、利用者アンケートを5段階で取り、回答速度だけでなく、回答の分かりやすさや業務に使える水準かまで見ておくと実態に近づきます。
再作業率は軽視されがちですが、実務では収支を大きく左右します。
見かけ上は回答件数が増えていても、あとで人が全面修正しているなら、削減工数は伸びません。
誤回答率も同じで、単なる精度指標ではなく、差し戻しや確認工数を通じて人件費に跳ね返ります。
PoCの段階では、成功ケースだけでなく、エスカレーションになった件数、回答を取り消した件数、再入力が必要だった件数まで拾っておくと、本番運用時の負荷が読みやすくなります。
KPIは、定義と測定方法を先に固定することで比較可能になります。実務では、次のような形で1枚に整理すると役員説明までつなげやすくなります。
| 指標 | 定義 | 測定方法 | 目標値の置き方 | 意思決定に与える影響 |
|---|---|---|---|---|
| 応答時間短縮 | 問い合わせ受領から初回回答までの時間短縮 | 導入前後の平均時間を比較 | 現行比で短縮 | 顧客対応力と待ち時間改善を判断 |
| 削減工数 | 人手対応から削減された作業時間 | 1件あたり削減時間 × 月間件数 | 月間削減時間で設定 | 人件費換算とROI算定に直結 |
| 対応件数 | 一定期間に処理できた件数 | 月次の完了件数を集計 | 現行比で増加 | 人員追加なしでの処理能力を判断 |
| 満足度 | 利用者・顧客の評価 | 5段階アンケートなどで集計 | 現状維持または改善 | 速度だけでなく受容性を確認 |
| 再作業率 | AI出力を人が再修正した割合 | 修正発生件数 ÷ 全処理件数 | 低下を目標化 | 隠れ工数の把握に有効 |
| 1件あたりAPIコスト | 1処理あたりのAPI費用 | 月間API費用 ÷ 月間処理件数 | 上限単価を設定 | 件数増加時の採算ラインを判断 |
| 誤回答率 | 業務上使えない回答の割合 | NG判定件数 ÷ 全回答件数 | 許容範囲内に設定 | 品質事故や有人介入量を判断 |
実際の運用では、役員向け報告でAPIコスト/件と削減工数/件を並べて見せると、合意形成が一気に進む場面が多くあります。
コストだけだと「AI利用料の話」に閉じますが、同じ行に「1件あたり何分減ったか」を置くと、収益構造の話に変わるからです。
技術部門と業務部門の会話がかみ合わないときも、この2つを並列にすると論点が揃います。
ROIの式と再現可能な試算テンプレート

ROIを見るときの出発点は、まず月間削減額を人件費ベースで置くことです。
基本式はシンプルで、月間削減額=削減工数(時間)× 時給 × 対象人数です。
これなら、問い合わせ対応、要約、翻訳、社内ヘルプデスクのどれでも同じ考え方で計算できます。
PoC段階では、理想値をそのまま使うのではなく、実運用で取りこぼす分を見込んだ保守的な係数をかけて評価すると、稟議で数字が崩れません。
公開されている試算例として、月30時間短縮、時給3,000円、対象者10人なら、月間削減額は約90万円になります。
計算は30時間 × 3,000円 × 10人で、900,000円です。
この数字そのものを採用するというより、自社の担当人数、実際の時給、削減できる時間に差し替えて再計算するのが実務です。
わかりやすく言うと、参考値は「式の使い方」を示しているだけで、経営判断に使う数字は必ず自社条件で作る必要があります。
再現可能な形にするなら、試算は次の順で組むとぶれません。
- 対象業務を1つに絞る
- 1件あたりの現行作業時間を測る
- AI導入後の人手介入時間を測る
- 差分を1件あたり削減工数として置く
- 月間件数を掛けて月間削減工数を出す
- 時給と対象人数を掛けて月間削減額に変換する
- API費用と運用費を引いてROIを確認する
たとえば、問い合わせ一次対応で1件あたりの削減工数が積み上がる業務では、月間件数との掛け算で効果が一気に見えてきます。
逆に、件数が少ない専門業務では、1件あたりAPIコストが低くても削減額が伸びにくいため、収益インパクトは限定的です。
ここで効いてくるのが、対応件数と再作業率を一緒に見る視点です。
件数が増えても再作業率が高ければ削減工数は目減りしますし、満足度が下がれば現場定着も進みません。
月間削減額のテンプレートは、次のように置くと社内で横展開しやすくなります。
| 項目 | 入れる値 | 計算内容 |
|---|---|---|
| 1件あたり現行作業時間 | 自社実測値 | 導入前の平均対応時間 |
| 1件あたり導入後作業時間 | 自社実測値 | AI利用後の平均対応時間 |
| 1件あたり削減工数 | 上記の差分 | 現行作業時間 − 導入後作業時間 |
| 月間対応件数 | 自社実績値 | 月内の総処理件数 |
| 月間削減工数 | 自動計算 | 1件あたり削減工数 × 月間対応件数 |
| 時給 | 自社基準値 | 対象業務の人件費単価 |
| 対象人数 | 自社実態 | 利用部門または対象担当者数 |
| 月間削減額 | 自動計算 | 月間削減工数 × 時給 × 対象人数 |
| 月間API費用 | 実測値 | API利用料の月額合計 |
💡 Tip
この表のよいところは、月間削減額の根拠が分解できる点です。
役員会では「その効果はどこから出た数字か」と問われますが、1件あたりの削減工数、対応件数、時給に分けておけば、仮定の置き方が明確になります。
PoCでは、削減工数を満額で評価せず、一部だけ業務削減として認める形にしておくと、保守的な試算になります。
💡 Tip
収支を見るときは、月額合計だけでなく、1件あたりAPIコストと1件あたり削減工数を対応づけると、件数増加時の採算ラインが見えます。月次で黒字でも、件数構成が変わると採算が崩れる業務は珍しくありません。
役員報告のフォーマット例
役員報告では、技術の仕組みを長く説明するより、意思決定に必要な数字を1枚で見せる方が通りやすくなります。
見る項目は、対象業務、導入目的、主要KPI、月間削減額、月間費用、品質面の懸念、今後の判断判断材料になります。
この順で並べると、「なぜやるのか」「いくら効くのか」「どんなリスクがあるのか」が短時間で伝わります。
実務で通りやすい形は、冒頭に結論を置くフォーマットです。
たとえば「問い合わせ一次対応で応答時間を短縮し、月間削減額は約90万円相当。
API費用は件数連動。
再作業率が許容範囲内なら対象部門を拡大」という構成です。
その下にKPI表を置き、応答時間短縮、削減工数、対応件数、満足度、再作業率、誤回答率、1件あたりAPIコストを並べます。
経営層は、個別ログよりも「収支と品質のバランス」を見ています。
フォーマット例を文章で表すと、次のような並びになります。
まず対象業務と現状課題を一文で示し、その次に施策としてChatGPT APIをどこに組み込んだかを書く。
続けて、PoCまたは本番運用で得られたKPIを表で掲載し、月間削減額の計算式を添える。
そのうえで、API費用と比較した差額を示し、再作業率や誤回答率が事業上許容できる水準かを評価します。
ここまで揃うと、役員会では「導入するか」ではなく「どこまで広げるか」の議論に移れます。
役員向けの1ページ資料に落とすなら、次の表現が実務では扱いやすい構成です。
| 項目 | 記載内容の例 |
|---|---|
| 対象業務 | 問い合わせ一次対応、社内ヘルプデスク、要約作業など |
| 現状課題 | 応答遅延、担当者負荷、処理件数の頭打ち |
| 導入施策 | ChatGPT APIを用いた一次回答自動化、下書き生成、分類補助 |
| 主要KPI | 応答時間短縮、削減工数、対応件数、満足度、再作業率、誤回答率、1件あたりAPIコスト |
| 月間削減額 | 削減工数(時間)× 時給 × 対象人数 |
| 月間費用 | API利用料、運用保守の社内負荷 |
| 判断条件 | 再作業率が高止まりしないこと、満足度が維持されること |
| 次の意思決定 | 部門拡大、対象業務の追加、モデルや処理方式の見直し |
このフォーマットで特に効くのは、月間削減額の試算例を固定の数式で置き、KPIの数字を毎月更新する運用です。
役員報告は一度きりの説得ではなく、継続判断の材料づくりです。
応答時間短縮や対応件数の伸びが見えていても、再作業率が悪化していれば拡大判断は鈍ります。
逆に、1件あたりAPIコストが一定でも、削減工数が積み上がっていれば投資余地が見えてきます。
経営判断に必要なのは、AIの先進性ではなく、収支と品質が再現可能な形で説明できることです。
データ保持・Zero Data Retention・契約

ここで見るべきポイントは、データ保持制御の選択肢とZero Data Retentionの扱いです。
保持方針や法人向けの条件は変わるため、見積もりや契約の際は公式ドキュメントを参照してください(参照例: OpenAI データ使用ポリシー のセキュリティ/コンプライアンス情報 2026-03-20)。
APIキーは「作る」より「配る」「保管する」「失効させる」の設計が難所です。
ソースコードへの直書き、チャットでの共有、個人端末への平文保存は、いずれも事故の入口になります。
鍵は用途別・環境別に分け、ローテーションの周期と失効手順を決めておく方が安全です。
1本のキーで開発、検証、本番を横断すると、漏えい時の影響範囲が読めません。
反対に、キーを分離しておけば、停止判断も限定的にできます。
監査ログも、残すこと自体より、何を追跡したいのかを先に定義しておく方が実務では効率的です。
最低限見えるようにしたいのは、誰が、いつ、どのシステムから、どの機能を呼び出したかという軸です。
そこに加えて、設定変更、キー発行、キー失効、権限変更の履歴が取れていると、障害対応と内部統制の両方で使えます。
ログの保存先が分散していると、インシデント時に時系列がつながらず、原因究明が遅れます。
アプリ側、認証基盤側、クラウド側の記録をつなげて見られる構成が望まれます。
誤送信防止の設計も見落としやすい判断材料になります。
問い合わせフォームや社内チャットからAPIへ渡す前に、個人情報や機密情報を検知して止めるのか、マスキングして送るのか、あるいは送信禁止項目としてルール化するのかで、統制レベルは変わります。
たとえば氏名、電話番号、メールアドレス、口座情報、契約番号、診療情報のようなPIIや機密データは、入力段階で置換する運用が有効です。
人が気をつける前提だけでは、繁忙時に抜けます。
入力フォーム、業務システム、連携基盤のどこでマスクするかまで決めておくと、再現性が出ます。
💡 Tip
本番運用では、アクセス権限、APIキー、監査ログ、マスキング設定を別々に管理しない方が運用負荷を抑えられます。変更申請の単位をそろえると、承認漏れや設定の食い違いが減ります。
個人情報・機密情報の取り扱いとレビュー体制
個人情報や機密情報の扱いでは、「送らない」が唯一の正解になる業務もあります。
契約確定判断、人事評価の最終決定、医療判断のように、誤回答そのものが事業リスクや法的リスクへ直結する領域は、人のレビューを前提に置くべきです。
前述の通り、生成AIは反復業務や下書き生成には強い一方、責任判断の代行には向きません。
この線引きが曖昧なまま本番化すると、便利さがそのまま統制不備になります。
そのため、導入時は情報の分類とレビュー体制をセットで設計する必要があります。
実務では、入力データを「公開情報」「社内限定」「機密」「個人情報含む」に分け、それぞれに対してAPI送信可否、マスキング要件、レビュー要否を定める形が運用に乗りやすいのが利点です。
たとえば公開情報の要約は自動処理、社内限定文書の要約は担当者レビュー付き、個人情報を含む問い合わせは匿名化後に処理、機密契約文書は送信対象外、というように、扱いを業務ルールへ落とし込みます。
レビュー体制では、誤回答が起きたときの対応プロセスを先に決めておくことが欠かせません。
誰が一次切り分けを行い、どのログを確認し、利用者へどう訂正し、再発防止をどこまで記録するのかが曖昧だと、現場は「とりあえず停止」に寄りがちです。
停止判断しか選べない運用は、導入効果の継続検証も止めてしまいます。
責任分界を明文化し、プロダクト側、業務部門側、法務・情報システム側の役割を分けておくと、障害時も混乱が少なくなります。
人的レビューの置き方にもコツがあります。
全件レビューでは工数が戻ってしまいますが、無審査運用では品質事故の確率が上がります。
現実的なのは、一定条件に引っかかった出力だけをレビュー対象に回す方式です。
たとえば、個人情報を含む可能性がある入力、重要顧客向け文面、法的表現を含む回答、社外送信前の文章などに限定すると、リスクの高い場面へ人的確認を集中できます。
経営的に見ると、レビューはコストではなく、誤回答の損失を限定するための保険設計です。
法務・ガバナンスの観点では、利用規約への同意、委託先管理、社内規程、教育、例外申請の流れまで含めて初めて運用になります。
APIを入れた瞬間にガバナンスが完成するわけではありません。
部門ごとに勝手な使い方が広がると、同じ会社の中で保持方針もレビュー基準もばらばらになります。
だからこそ、技術導入の議論と並行して、どの業務は使ってよく、どの業務は人が判断を持つのかを整理しておく必要があります。
この整理ができている組織ほど、PoCから本番への移行で失速しません。
まとめ|最初は小さく始め、費用と効果を同時に検証する

小さく始めて、費用と効果を同じ土俵で見る進め方が、導入判断の精度を上げます。
着手時点では、小規模PoCで1業務に絞り、用途別にAPIを使い分ける前提で設計すると、過剰投資を避けながら現実的なコスト最適化が進みます。
見るべき軸は、単なる利用料ではなく、速度・コスト・品質のKPIで業務成果まで含めて測ることです。
即時性が要らない処理はBatch API候補に切り分け、料金はその都度OpenAI公式Pricingで確認しながら検証を進める形が堅実です。
機密情報を扱う業務では、データ保持と契約条件の確認も着手条件に含めておくと、PoC後の横展開で止まりません。
関連記事(同一ページ内アンカー): 導入の進め方5ステップ、コストを抑える方法
大手コンサルティングファームで中小企業向けDX推進コンサルティングに5年間従事。AI導入プロジェクトのPoC設計から効果測定まで一貫して支援した経験を持つ。
関連記事
オフショアAI開発の人月単価|国別相場と発注の注意点
オフショアAI開発の人月単価|国別相場と発注の注意点
オフショアAI開発の見積もりは、国名だけで見ても答えが出ません。プログラマーの人月単価は6カ国平均で約34万円、最安のミャンマー約27.5万円から中国約58.3万円まで2倍以上の開きがあり、2026年はインドが-29.6%、フィリピンが-13.5%、ベトナムが+1.8%と動きも分かれています。
社内AIチャットボット導入費用と作り方
社内AIチャットボット導入費用と作り方
社内AIチャットボットは、従業員10〜100名規模の中小企業で情シスや総務を兼任する担当者が、社内問い合わせの山を減らすために導入を検討する仕組みである。中村俊介の現場感で見ると、月額だけを見て安いツールを選び、社内データの整備工数を見落として使われずに終わる失敗が繰り返されてきました。
AI顧問の費用相場|月額料金プラン3パターンと失敗しない選び方
AI顧問の費用相場|月額料金プラン3パターンと失敗しない選び方
AI顧問サービスは、中小企業向けでは月額10万〜35万円が中心帯で、助言だけの月額4万〜10万円、CAIO代行・戦略立案型の月額30万〜100万円と明確に層が分かれています。
AIエンジニア単価相場2026|経験年数・スキル領域別の月額早見表
AIエンジニア単価相場2026|経験年数・スキル領域別の月額早見表
AIエンジニアの単価は、2026年時点でフリーランス平均90.6万円とIT関連職種の上位水準です。生成AI・LLM活用やLLMOpsの経験を持つ人材は、月額90〜130万円、条件がそろえばそれ以上のレンジも見えてきます。